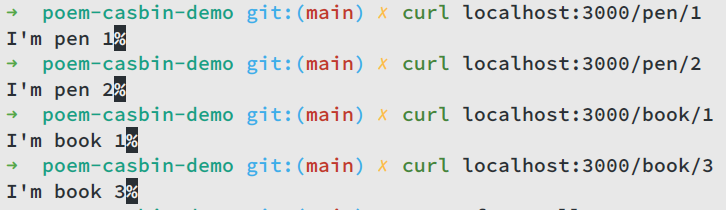
There are 3 endpoints, /pen/1, /pen/2, and /book/:id. It’s quite simple, right? Let’s run our service, enter cargo run and our service will be available at 127.0.0.1:3000.
Let’s use curl to test our service:
Integrate with basic auth middleware
Note that casbin-poem is an authorization middleware, not an authentication middleware. Casbin only takes charge of permission control, so we need to implement an authentication middleware to identify user.
In this part, we will inegrate our service with a basic auth middleware.
To start with, add following dependency to Cargo.toml:
In this mod, we implement a basic auth middleware, for simplicity, here we don’t verify username and password, instead we just insert CasbinVals with provided username into Extension,so that poem-casbin middleware can extract identity information. If the request doesn’t have basic auth, then the middleware will return 401 Unauthorized.
Then let’s integrate our service with basic auth middleware. Firstly, add following code to main.rs:
1 2 3
mod auth;
use poem_casbin_auth::CasbinVals;
Then add a new handler to confirm that our auth middleware insert identity information correctly:
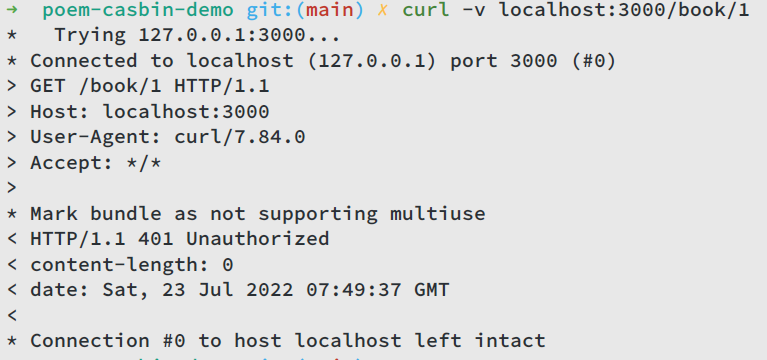
Now as you can see, if we don’t provide basic auth when accessing our service, we will get 401 Unauthorized. Our request is aborted by basic auth middleware. Let’s send requests with basic auth:
1
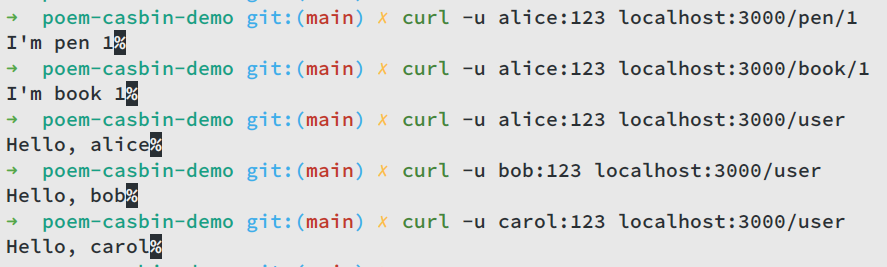
curl -u alice:123 localhost:3000/book/1
Now we can get response as normal. It seems that our basic auth middleware works well.
Integrate with poem-casbin middleware
In the last part, we will integrate our service with poem-casbin middleware.
First, we need to provide conf and policy files under the project root directory.
p, alice, /pen/1, GET p, book_admin, book_group, GET p, pen_admin, pen_group, GET ,,, g, alice, book_admin, g, bob, pen_admin, g2, /book/:id, book_group, g2, /pen/:id, pen_group,
These policy means:
For alice:
can access /pen/1
is book_admin, thus can access /book/:id
For bob:
is pen_admin, thus can access /pen/:id
Now let’s focus on main.rs, first add following code to it:
1 2 3
use poem_casbin_auth::casbin::function_map::key_match2; use poem_casbin_auth::casbin::{CoreApi, DefaultModel, FileAdapter}; use poem_casbin_auth::{CasbinService, CasbinVals};
Then rewrite main function to wrap our service with poem-casbin middleware:
Here we first read conf and policy, then create casbin_middleware and change matching_fn to key_match to match wildcard path (like /:id). Lastly, we wrap all endpoints with casbin_middleware.
That’s all the work we have to do to integrate our service with poem-casbin middleware, quite simple, right?
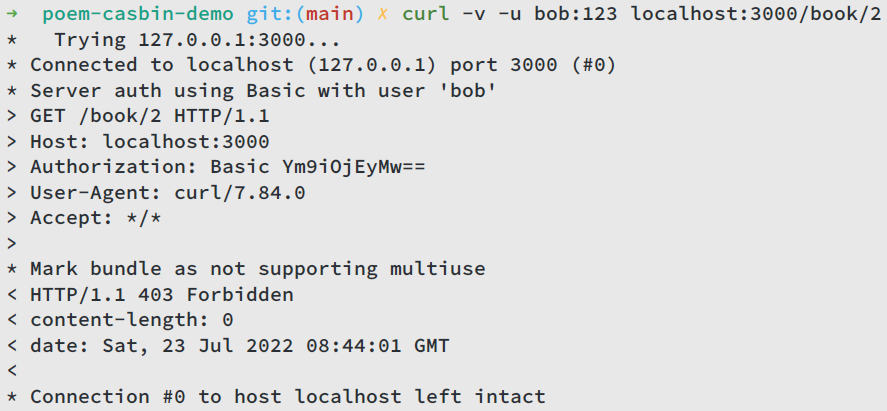
Again, let’s use curl to test our service:
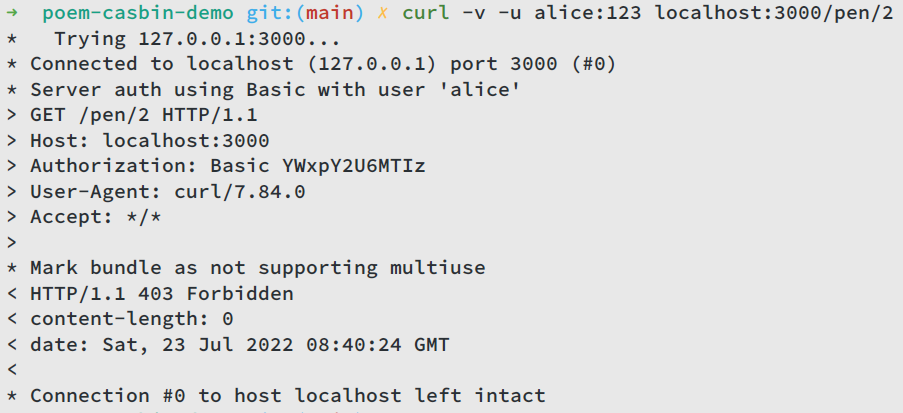
If alice wants to access /pen/2, she will get 403 Forbidden, because she is not allowed to access this endpoint.
Likewise, bob can’t access /book/2:
Everything is fine when both users send requests to the endpoints that they can access:
Summary
In this tutorial, we write a hello-world web service using poem, then integrate it with basic auth and casbin-poem middleware. It’s a quite simple project with only ~100 LOC, its code can be found at this repository: https://github.com/greenhandatsjtu/poem-casbin-demo
First I add CI for poem-casbin, ci.yml is bases on which from actix-casbin-auth, but I made some minor changes: change branch name from master to main , and upgrade actions/checkout to v3.
The workflow will run following checks when there’s push/pull_request to main branch:
cargo build
cargo test --no-default-features --features runtime-tokio
cargo test --no-default-features --features runtime-async-std
cargo clippy -- -D warnings
cargo fmt --all -- --check
This is what we got:
Then I started to add some tests and examples to poem-casbin, I also use actix-casbin-auth as reference, it has 3 test files:
test_middleware.rs: test basic middleware function
test_middleware_domain.rs: test middleware function with domain
test_set_enforcer.rs: test initializing middleware using set_enforcer()
In the tests, first it implements a fake authentication middleware called FakeAuth, which just simply insert a CasbinVals with subject alice and domain domain1 to request’s exetensions:
// send request letresp = cli.get("/").send().await; // check the status code resp.assert_status_is_ok(); // check the body string resp.assert_text("hello").await;
And poem use with to wrap endpoints with middlewares:
Note this middleware only takes care of authorization, so user should put actix_casbin_auth::CasbinVals which contains subject(username) and domain(optional) into extension before calling this middleware.
After learning actix-casbin-auth I’m clear about what work casbin middleware does. So I turned to learn how to write poem middleware.
There are not many tutorial on implementing middleware for poem, but poem provides bunch of middleware examples in https://github.com/poem-web/poem/tree/master/examples/poem . So I took a look at these examples and figured out how to implement middleware for poem.
Just like actix, we have to implement two traits: Middleware and Endpoint.
Middleware is like Transform in actix, it wraps other services, it looks like:
1 2 3 4 5 6 7
pub traitMiddleware<E:Endpoint> { /// New endpoint type. typeOutput:Endpoint;
/// Transform the input[`Endpoint`] to another one. fntransform(&self, ep: E) ->Self::Output; }
Endpoint is like Service in actix, it takes a request and returns a response, it looks like:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
pubtraitEndpoint: Send + Sync { /// Represents the response of the endpoint. typeOutput: IntoResponse;
/// Get the response to the request. asyncfncall(&self, req: Request) ->Result<Self::Output>;
/// Get the response to the request and return a [`Response` asyncfnget_response(&self, req: Request) -> Response { self.call(req) .await .map(IntoResponse::into_response) .unwrap_or_else(|err| err.into_response()) } }
Now I know how to write middleware in poem, so I start implementing casbin middleware for it, this is my first PR:
The DATABASE_URL environment variable must be set at build-time to point to a database server with the schema that the query string will be checked against. All variants of query!() use dotenv so this can be in a .env file instead.
Or, sqlx-data.json must exist at the workspace root.
query! can be configured to not require a live database connection for compilation, but it requires a couple extra steps:
Run cargo install sqlx-cli.
In your project with DATABASE_URL set (or in a .env file) and the database server running, run cargo sqlx prepare.
Check the generated sqlx-data.json file into version control.
Don’t have DATABASE_URL set during compilation.
Your project can now be built without a database connection (you must omit DATABASE_URL or else it will still try to connect). To update the generated file simply run cargo sqlx prepare again.
Note: As sqlx-adapter has generated sqlx-data.json for postgres, so when using postgres you don’t need provide DATABASE_URL or sqlx-data.json . But for mysql and sqlite, you must provide DATABASE_URL or sqlx-data.json
However, it would be better if we can generate sqlx-data.json for all three kinds of database in sqlx-adapter , so users won’t bother setting DATABASE_URL or generating sqlx-data.json by themselves. I’ve been tried a while but found cargo sqlx prepare would just overwrite sqlx-data.json.
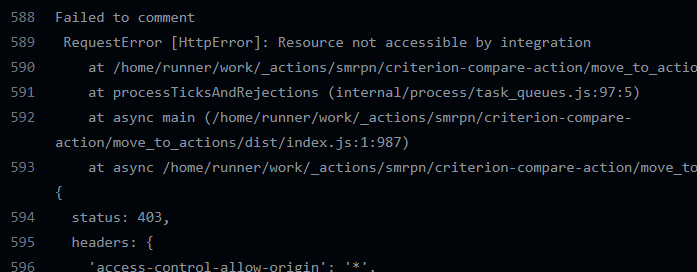
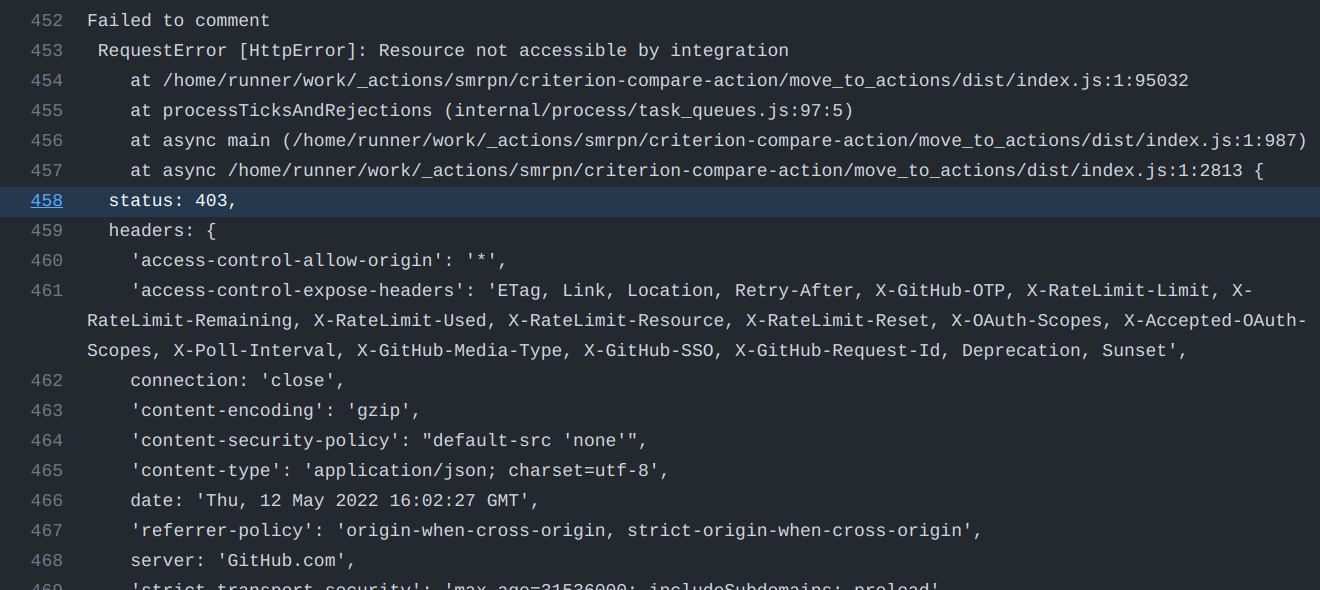
The reason is GITHUB_TOKEN only has read permission to pull requests when access by forked repos, so when a new PR is coming, running workflows only has read-only permission (of course not allowed to post comment), that’s why we get 403 here: https://github.com/casbin/casbin-rs/runs/6409294114#step:5:459
Some users have created actions that can post comment on PR, like:
The event runs against the workflow and code from the base of the pull request. This means the workflow is running from a trusted source and is given access to a read/write token as well as secrets enabling the maintainer to safely comment on or label a pull request.
I give this a try.
I first created a PR from a fork repo:
It fails as before.
Then I modify pull_request.yml to use pull_request_target , then create another PR.
Last week another guy was assigned to this project too, so this week I discussed with him, as he said he has written ~100 lines of code, I think it’s better that he made an initial PR to upload SDK framework, then we can make PRs to complete it .
The key of HashMap<String, HashMap<String, Arc<RwLock<Role>>>> is domain name (default value is DEFAULT), the key of HashMap<String, Arc<RwLock<Role>>> is role name, the entry is Arc<RwLock<Role>> , which stores role information: name of the role, and all roles it directly has
It is quite expensive as Arc<T> uses atomic ****operations for its reference counting, and there are many read() and write() operations for RwLock<Role> in current implmentation:
has_link check if role name1 has role name2 (dosen’t have to be direct role), if domain_matching_fn is speicified, it will find roles in matched domains
get_roles get all direct roles user name has in matched domains
get_users get all users that directly have role name in matched domains
type Role struct { name string roles *sync.Map users *sync.Map matched *sync.Map matchedBy *sync.Map }
But instead of using map and storing related roles’ pointers in them, it use StableDiGraph to construct roles graph, and use edges EdgeVariant to represent relations:
1 2 3 4
enumEdgeVariant { Link, Match, }
Edges with the EdgeVariant::Link are relations which in Go are modeled by the roles and users map. Edges with the EdgeVariant::Match are relations which is Go are modeled by the matched and matchedBy map.
This PR gets rid of Arc<RwLock<Role>> by using StableDiGraph and NodeIndex :
StableGraph<N, E, Ty, Ix> is a graph datastructure using an adjacency list representation, all_domains constructs a StableGraph with directed edges for each domain, all_domains_indices stores node identifier NodeIndex of every role node in the graph
Important functions:
get_or_create_role
get or create role;
if the role is new, graph.add_node() to add role to grapgh;
if role_matching_fn is specified, call link_if_matches to match existing roles against new role and vice versa, if matched, call graph.add_edge() to create EdgeVariant::*Match* edge between roles.
add_link
add link from role1 to role2 , call graph.add_edge() to add EdgeVariant::*Link edge*
delete_link
remove edge from role1 to role2
has_link
Bfs searching in graph, checking if role1 is connected to role2
get_roles
Bfs searching in graph, getting all roles the user directly has
get_users
Find all nodes having Direction::*Incoming* edge connected to this role, that is, getting all users that directly have this role
Why Performance impoved?
In StableGraph, nodes (roles) and edges (relations) are each numbered in an interval from 0 to some number m, so we can access nodes and edges using their indices, also, creating a role is just adding a node to graph, link roles is justing add an edge between 2 nodes, we don’t have to modify nodes and edges, so Arc and RWLock are no longer needed.
Without atomic operations and lock/unlock, role manager is much faster now.
Tests
The PR add 2 tests:
test_basic_role_matching test user with wildcard *
test_basic_role_matching2 test role with wildcard *
role_manager_test.go:371: alice: [* book_group alice book_group bob pen_group], supposed to be [* alice bob book_group pen_group]
Note that book_group appears twice, this is because in (*Role).rangeRoles :
1 2 3 4 5 6 7 8 9 10 11 12 13
func(r *Role) rangeRoles(fn func(key, value interface{})bool) { r.roles.Range(fn) r.roles.Range(func(key, value interface{})bool { role := value.(*Role) role.matched.Range(fn) returntrue }) r.matchedBy.Range(func(key, value interface{})bool { role := value.(*Role) role.roles.Range(fn) returntrue }) }
All roles, matched, and matchedBy roles are appended to result, which is a list, whille casbin-rs uses HashSet , so there are no duplicate in casbin-rs.
issue: As I said above, when reviewing PR, I found a bug in Go version casbin. In default-role-manager/role_manager.go, func (r *Role) getRoles() returns result with duplicate items
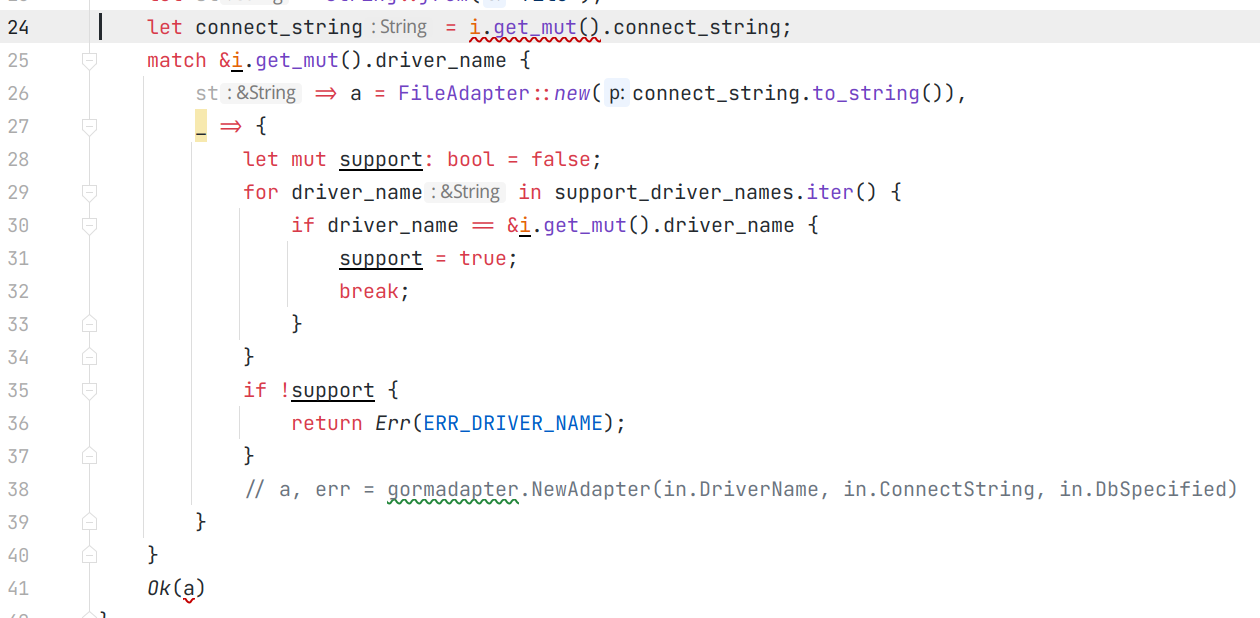
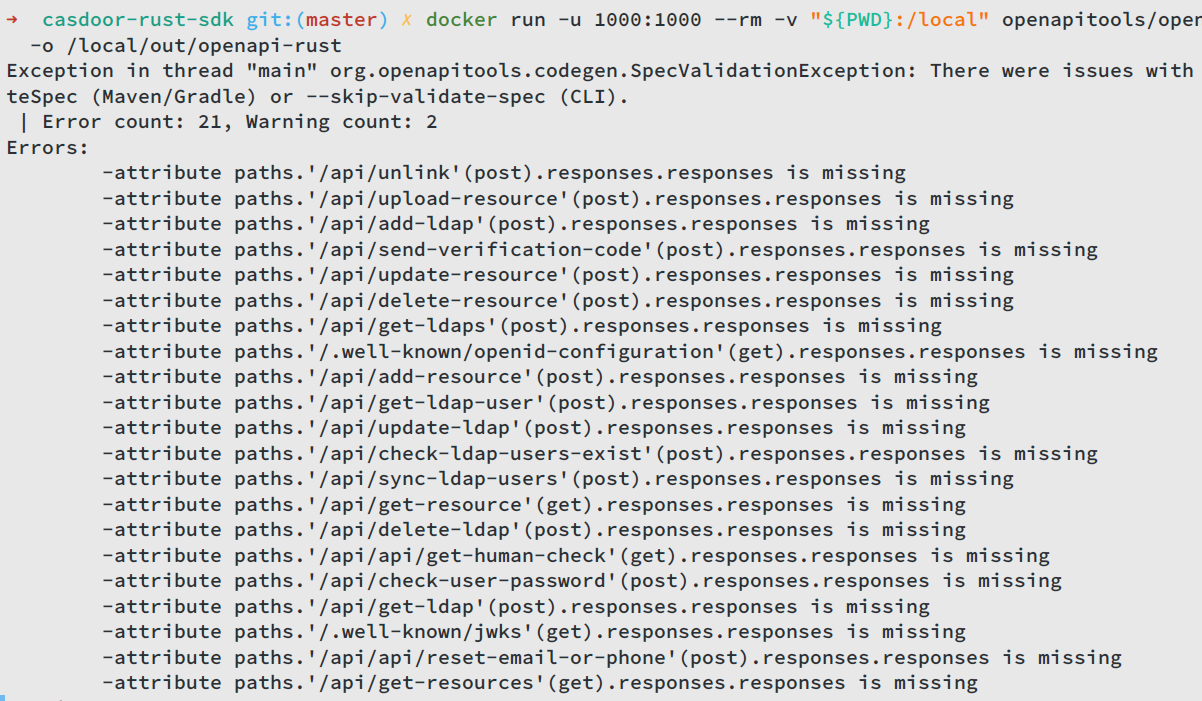
There are 105 enpoints in casdoor now, so when developing casdoor rust sdk, I have to write many similar and duplicate code. To avoid this, I first looked for code generator.
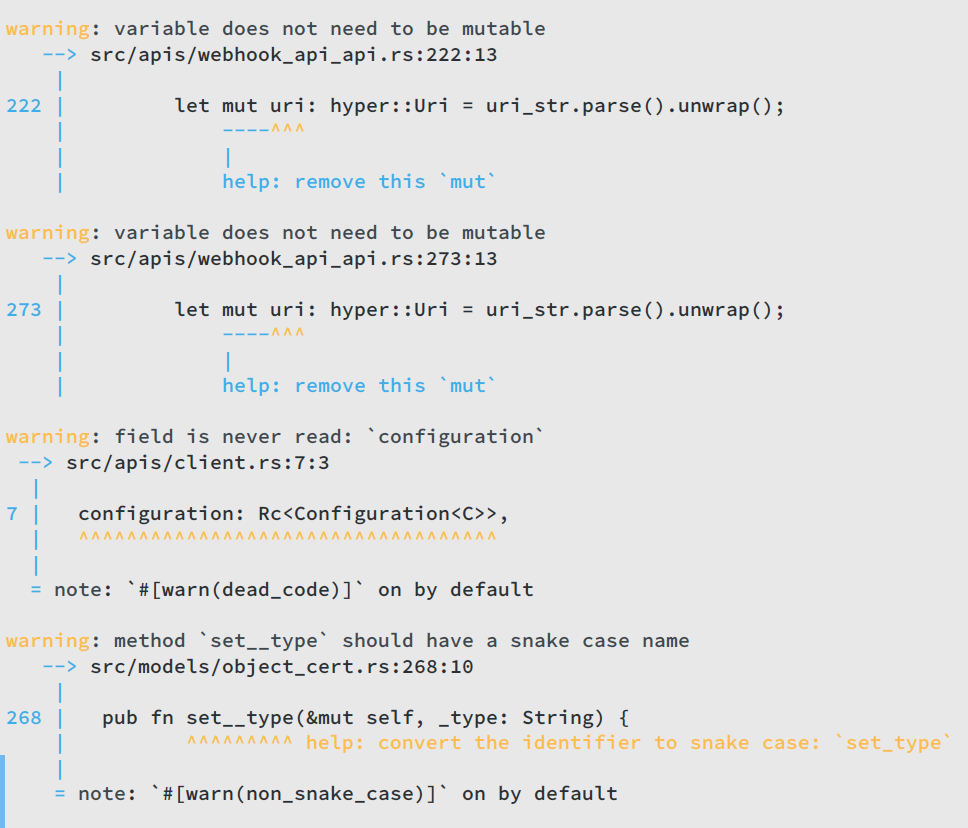
However, when running cargo build , I got many warnings like:
After searching a while on the web, I found work around (https://stackoverflow.com/a/57641467): add #![allow(warnings)] at the first line in src/lib.rs
Now cargo build doesn’t produce warnings now.
However, as the warnings are still here, this doesn’t help much, there are still many deprecated code and badly named variables.
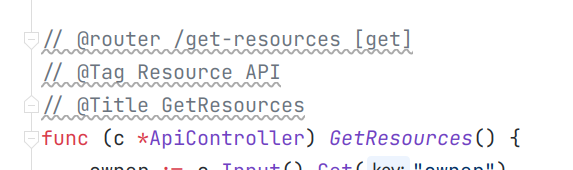
It says that because some endpoints in swagger.yml aren’t providing response, so the spec validation failes. For example, GetResources endpoint is not well annotated (no params, no response)
Welcome to Hexo! This is your very first post. Check documentation for more info. If you get any problems when using Hexo, you can find the answer in troubleshooting or you can ask me on GitHub.